
Synthetic intelligence (AI) is a quickly evolving area with the potential to enhance and rework many facets of society. In 2023, the tempo of adoption of AI applied sciences has accelerated additional with the event of highly effective basis fashions (FMs) and a ensuing development in generative AI capabilities.
At Amazon, we’ve got launched a number of generative AI companies, akin to Amazon Bedrock and Amazon CodeWhisperer, and have made a variety of extremely succesful generative fashions accessible by means of Amazon SageMaker JumpStart. These companies are designed to assist our clients in unlocking the rising capabilities of generative AI, together with enhanced creativity, customized and dynamic content material creation, and revolutionary design. They’ll additionally allow AI practitioners to make sense of the world as by no means earlier than—addressing language limitations, local weather change, accelerating scientific discoveries, and extra.
To understand the total potential of generative AI, nevertheless, it’s vital to rigorously mirror on any potential dangers. At the beginning, this advantages the stakeholders of the AI system by selling accountable and protected growth and deployment, and by encouraging the adoption of proactive measures to handle potential affect. Consequently, establishing mechanisms to evaluate and handle danger is a vital course of for AI practitioners to contemplate and has turn into a core part of many rising AI business requirements (for instance, ISO 42001, ISO 23894, and NIST RMF) and laws (akin to EU AI Act).
On this submit, we talk about find out how to assess the potential danger of your AI system.
What are the completely different ranges of danger?
Whereas it is perhaps simpler to start out taking a look at a person machine studying (ML) mannequin and the related dangers in isolation, it’s vital to contemplate the small print of the precise software of such a mannequin and the corresponding use case as a part of a whole AI system. In truth, a typical AI system is more likely to be based mostly on a number of completely different ML fashions working collectively, and a corporation is perhaps trying to construct a number of completely different AI techniques. Consequently, dangers might be evaluated for every use case and at completely different ranges, particularly mannequin danger, AI system danger, and enterprise danger.
Enterprise danger encompasses the broad spectrum of dangers that a corporation might face, together with monetary, operational, and strategic dangers. AI system danger focuses on the affect related to the implementation and operation of AI techniques, whereas ML mannequin danger pertains particularly to the vulnerabilities and uncertainties inherent in ML fashions.
On this submit, we give attention to AI system danger, primarily. Nevertheless, it’s vital to notice that each one completely different ranges of danger administration inside a corporation must be thought-about and aligned.
How is AI system danger outlined?
Threat administration within the context of an AI system could be a path to reduce the impact of uncertainty or potential damaging impacts, whereas additionally offering alternatives to maximise optimistic impacts. Threat itself is just not a possible hurt however the impact of uncertainty on aims. Based on the NIST Threat Administration Framework (NIST RMF), danger might be estimated as a multiplicative measure of an occasion’s likelihood of occurring timed by the magnitudes of the results of the corresponding occasion.
There are two facets to danger: inherent danger and residual danger. Inherent danger represents the quantity of danger the AI system reveals in absence of mitigations or controls. Residual danger captures the remaining dangers after factoring in mitigation methods.
At all times understand that danger evaluation is a human-centric exercise that requires organization-wide efforts; these efforts vary from guaranteeing all related stakeholders are included within the evaluation course of (akin to product, engineering, science, gross sales, and safety groups) to assessing how social views and norms affect the perceived probability and penalties of sure occasions.
Why ought to your group care about danger analysis?
Establishing danger administration frameworks for AI techniques can profit society at massive by selling the protected and accountable design, growth and operation of AI techniques. Threat administration frameworks may also profit organizations by means of the next:
- Improved decision-making – By understanding the dangers related to AI techniques, organizations could make higher choices about find out how to mitigate these dangers and use AI techniques in a protected and accountable method
- Elevated compliance planning – A danger evaluation framework may also help organizations put together for danger evaluation necessities in related legal guidelines and rules
- Constructing belief – By demonstrating that they’re taking steps to mitigate the dangers of AI techniques, organizations can present their clients and stakeholders that they’re dedicated to utilizing AI in a protected and accountable method
How one can assess danger?

As a primary step, a corporation ought to take into account describing the AI use case that must be assessed and establish all related stakeholders. A use case is a selected state of affairs or scenario that describes how customers work together with an AI system to attain a specific objective. When making a use case description, it may be useful to specify the enterprise drawback being solved, checklist the stakeholders concerned, characterize the workflow, and supply particulars concerning key inputs and outputs of the system.
In relation to stakeholders, it’s straightforward to miss some. The next determine is an effective start line to map out AI stakeholder roles.
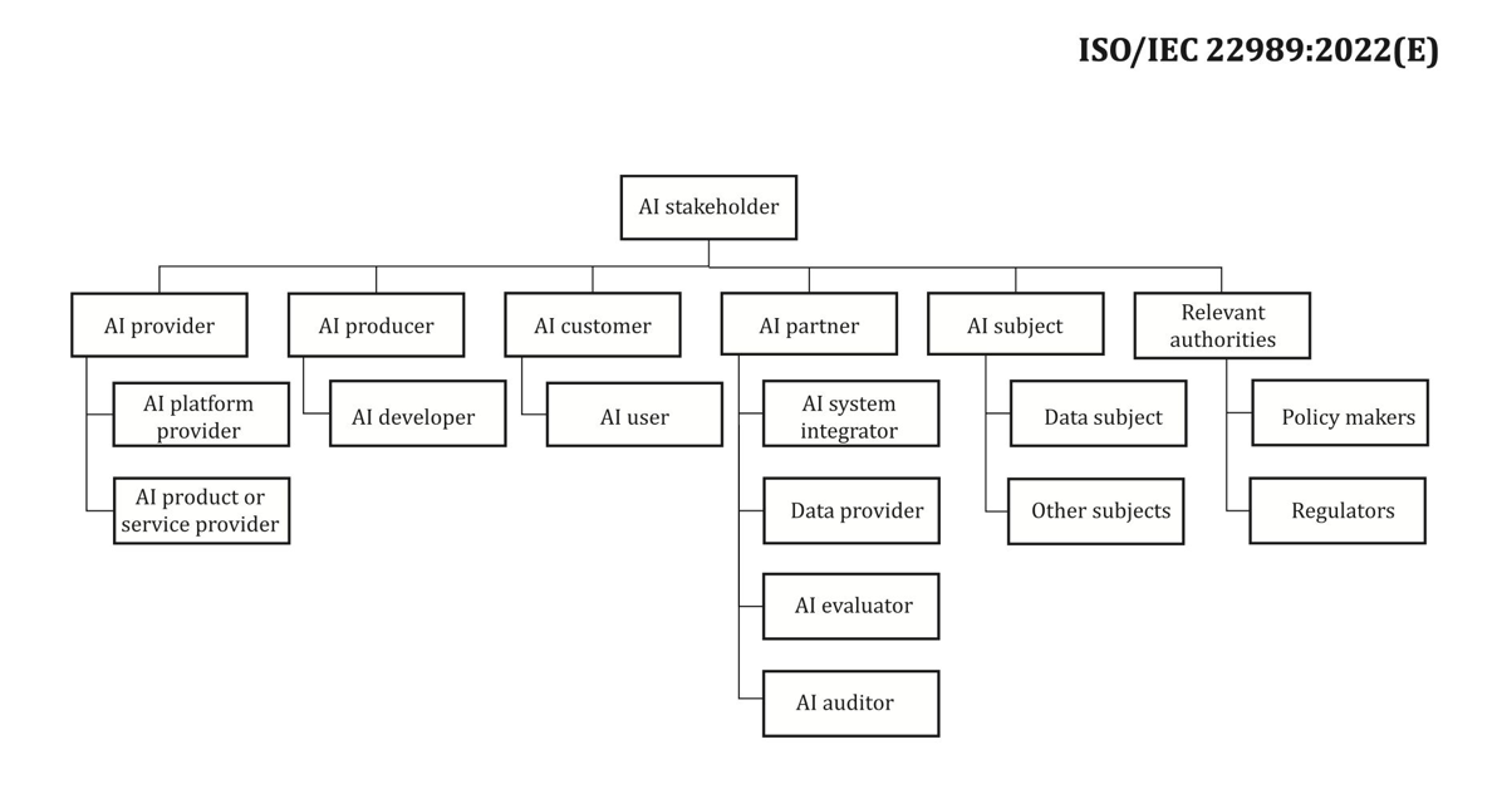
Supply: “Data expertise – Synthetic intelligence – Synthetic intelligence ideas and terminology”.
An vital subsequent step of the AI system danger evaluation is to establish probably dangerous occasions related to the use case. In contemplating these occasions, it may be useful to mirror on completely different dimensions of accountable AI, akin to equity and robustness, for instance. Completely different stakeholders is perhaps affected to completely different levels alongside completely different dimensions. For instance, a low robustness danger for an end-user may very well be the results of an AI system exhibiting minor disruptions, whereas a low equity danger may very well be attributable to an AI system producing negligibly completely different outputs for various demographic teams.
To estimate the chance of an occasion, you should utilize a probability scale together with a severity scale to measure the likelihood of prevalence in addition to the diploma of penalties. A useful start line when creating these scales is perhaps the NIST RMF, which suggests utilizing qualitative nonnumerical classes starting from very low to very excessive danger or semi-quantitative assessments ideas, akin to scales (akin to 1–10), bins, or in any other case consultant numbers. After you may have outlined the probability and severity scales for all related dimensions, you should utilize a danger matrix scheme to quantify the general danger per stakeholders alongside every related dimension. The next determine reveals an instance danger matrix.
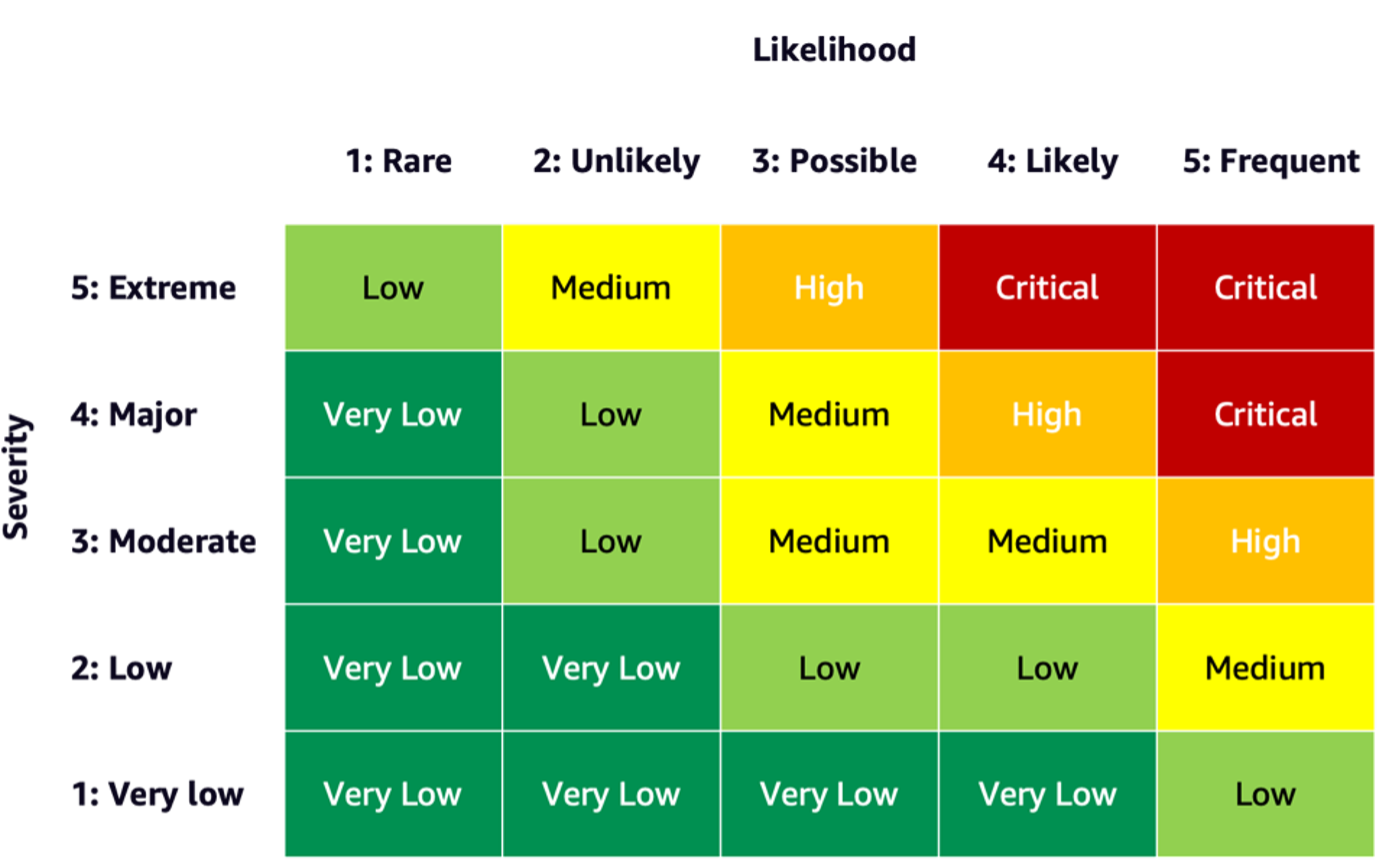
Utilizing this danger matrix, we are able to take into account an occasion with low severity and uncommon probability of occurring as very low danger. Needless to say the preliminary evaluation can be an estimate of inherent danger, and danger mitigation methods may also help decrease the chance ranges additional. The method can then be repeated to generate a score for any remaining residual danger per occasion. If there are a number of occasions recognized alongside the identical dimension, it may be useful to choose the best danger degree amongst all to create a ultimate evaluation abstract.
Utilizing the ultimate evaluation abstract, organizations should outline what danger ranges are acceptable for his or her AI techniques in addition to take into account related rules and insurance policies.
AWS dedication
By means of engagements with the White Home and UN, amongst others, we’re dedicated to sharing our information and experience to advance the accountable and safe use of AI. Alongside these strains, Amazon’s Adam Selipsky lately represented AWS on the AI Security Summit with heads of state and business leaders in attendance, additional demonstrating our dedication to collaborating on the accountable development of synthetic intelligence.
Conclusion
As AI continues to advance, danger evaluation is changing into more and more vital and helpful for organizations trying to construct and deploy AI responsibly. By establishing a danger evaluation framework and danger mitigation plan, organizations can scale back the chance of potential AI-related incidents and earn belief with their clients, in addition to reap advantages akin to improved reliability, improved equity for various demographics, and extra.
Go forward and get began in your journey of creating a danger evaluation framework in your group and share your ideas within the feedback.
Additionally try an summary of generative AI dangers revealed on Amazon Science: Accountable AI within the generative period, and discover the vary of AWS companies that may assist you in your danger evaluation and mitigation journey: Amazon SageMaker Make clear, Amazon SageMaker Mannequin Monitor, AWS CloudTrail, in addition to the mannequin governance framework.
Concerning the Authors
 Mia C. Mayer is an Utilized Scientist and ML educator at AWS Machine Studying College; the place she researches and teaches security, explainability and equity of Machine Studying and AI techniques. All through her profession, Mia established a number of college outreach packages, acted as a visitor lecturer and keynote speaker, and introduced at quite a few massive studying conferences. She additionally helps inner groups and AWS clients get began on their accountable AI journey.
Mia C. Mayer is an Utilized Scientist and ML educator at AWS Machine Studying College; the place she researches and teaches security, explainability and equity of Machine Studying and AI techniques. All through her profession, Mia established a number of college outreach packages, acted as a visitor lecturer and keynote speaker, and introduced at quite a few massive studying conferences. She additionally helps inner groups and AWS clients get began on their accountable AI journey.
 Denis V. Batalov is a 17-year Amazon veteran and a PhD in Machine Studying, Denis labored on such thrilling tasks as Search Contained in the Ebook, Amazon Cellular apps and Kindle Direct Publishing. Since 2013 he has helped AWS clients undertake AI/ML expertise as a Options Architect. At the moment, Denis is a Worldwide Tech Chief for AI/ML answerable for the functioning of AWS ML Specialist Options Architects globally. Denis is a frequent public speaker, you may comply with him on Twitter @dbatalov.
Denis V. Batalov is a 17-year Amazon veteran and a PhD in Machine Studying, Denis labored on such thrilling tasks as Search Contained in the Ebook, Amazon Cellular apps and Kindle Direct Publishing. Since 2013 he has helped AWS clients undertake AI/ML expertise as a Options Architect. At the moment, Denis is a Worldwide Tech Chief for AI/ML answerable for the functioning of AWS ML Specialist Options Architects globally. Denis is a frequent public speaker, you may comply with him on Twitter @dbatalov.
 Dr. Sara Liu is a Senior Technical Program Supervisor with the AWS Accountable AI crew. She works with a crew of scientists, dataset leads, ML engineers, researchers, in addition to different cross-functional groups to boost the accountable AI bar throughout AWS AI companies. Her present tasks contain creating AI service playing cards, conducting danger assessments for accountable AI, creating high-quality analysis datasets, and implementing high quality packages. She additionally helps inner groups and clients meet evolving AI business requirements.
Dr. Sara Liu is a Senior Technical Program Supervisor with the AWS Accountable AI crew. She works with a crew of scientists, dataset leads, ML engineers, researchers, in addition to different cross-functional groups to boost the accountable AI bar throughout AWS AI companies. Her present tasks contain creating AI service playing cards, conducting danger assessments for accountable AI, creating high-quality analysis datasets, and implementing high quality packages. She additionally helps inner groups and clients meet evolving AI business requirements.

/cdn.vox-cdn.com/uploads/chorus_asset/file/24007892/acastro_STK112_android_01.jpg)

